DMR 入门
开始使用 Docker Model Runner。
启用 Docker Model Runner
在 Docker Desktop 中启用 DMR
- 在设置视图中,转到 AI 选项卡。
- 选择 启用 Docker Model Runner 设置。
- 如果您在 Windows 上使用受支持的 NVIDIA GPU,您还会看到并可以选择 启用 GPU 加速推理。
- 可选:要启用 TCP 支持,请选择 启用主机端 TCP 支持。
- 在 端口 字段中,输入您要使用的端口。
- 如果您从本地前端 Web 应用程序与模型运行器交互,请在 CORS 允许来源 中,选择模型运行器应接受请求的来源。来源是您的 Web 应用程序运行的 URL,例如
https://:3131。
您现在可以在 CLI 中使用 docker model 命令,并在 Docker Desktop 仪表板的 模型 选项卡中查看和与本地模型交互。
重要提示对于 Docker Desktop 4.45 及更早版本,此设置位于 Beta 功能 选项卡下。
在 Docker Engine 中启用 DMR
确保您已安装 Docker Engine。
Docker Model Runner 可作为软件包提供。要安装它,请运行
$ sudo apt-get update $ sudo apt-get install docker-model-plugin$ sudo dnf update $ sudo dnf install docker-model-plugin测试安装
$ docker model version $ docker model run ai/smollm2
注意Docker Engine 默认在端口
12434上启用 TCP 支持。
在 Docker Engine 中更新 DMR
要在 Docker Engine 中更新 Docker Model Runner,请使用 docker model uninstall-runner 卸载它,然后重新安装它。
docker model uninstall-runner --images && docker model install-runner注意使用上述命令,本地模型将被保留。要在升级期间删除模型,请将
--models选项添加到uninstall-runner命令中。
拉取模型
模型在本地缓存。
注意当您使用 Docker CLI 时,您还可以直接从 HuggingFace 拉取模型。
- 选择 模型 并选择 Docker Hub 选项卡。
- 找到您想要的模型并选择 拉取。
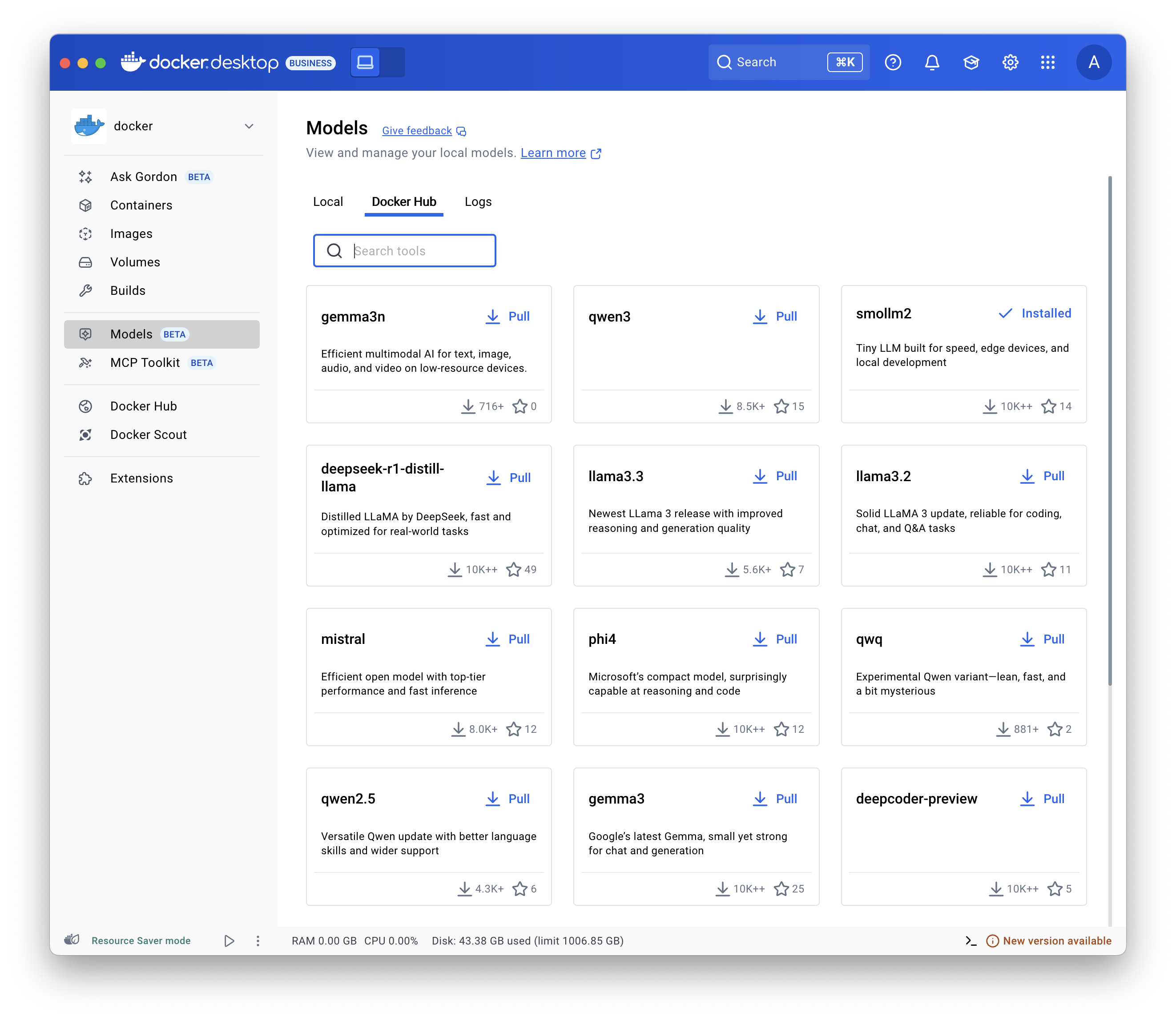
使用 docker model pull 命令。例如
docker model pull ai/smollm2:360M-Q4_K_Mdocker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUF运行模型
- 选择 模型 并选择 本地 选项卡。
- 选择播放按钮。交互式聊天屏幕打开。
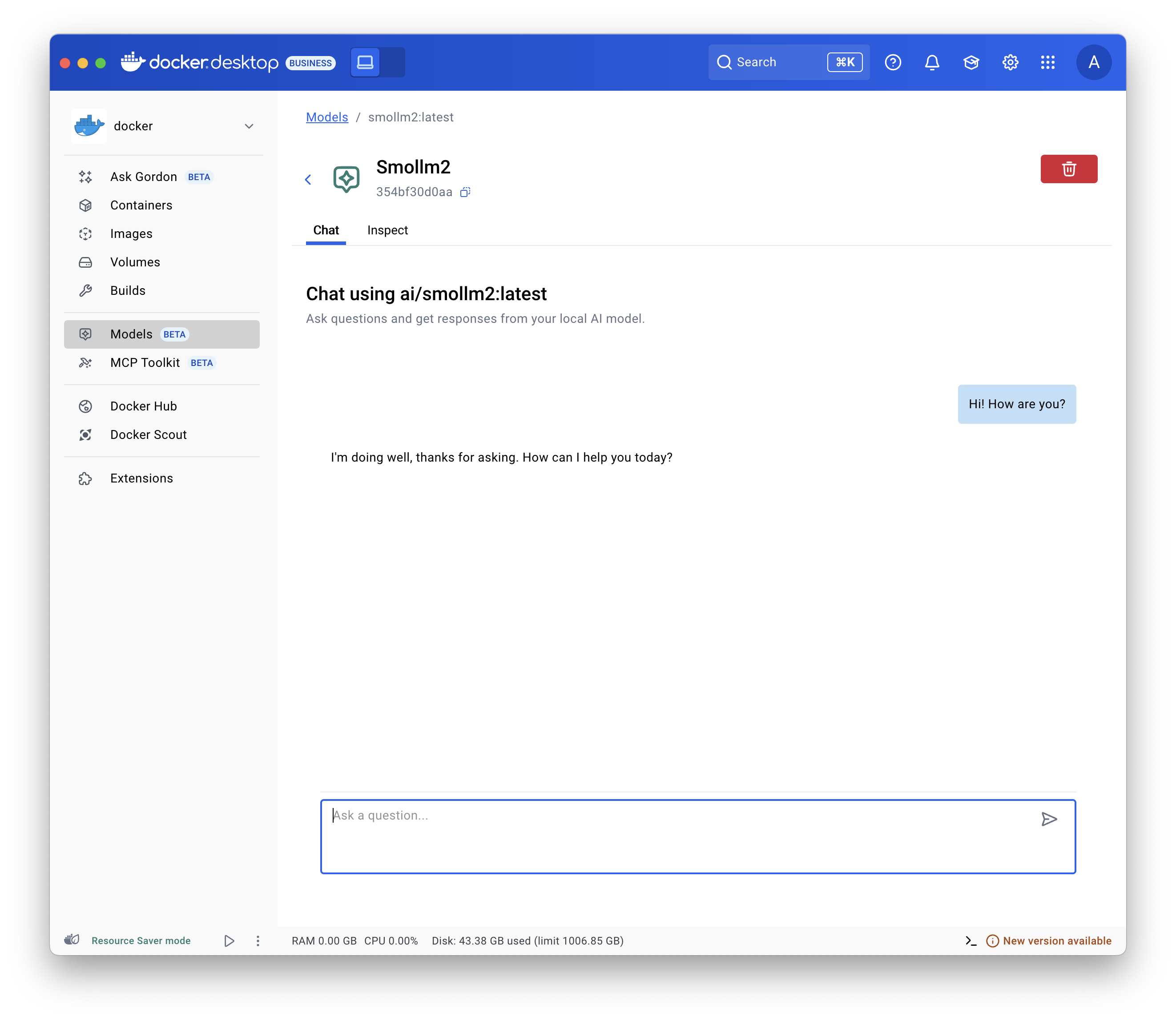
配置模型
您可以使用 Docker Compose 配置模型,例如其最大令牌限制等。请参阅 模型和 Compose - 模型配置选项。
发布模型
注意这适用于任何支持 OCI Artifacts 的容器注册表,而不仅仅是 Docker Hub。
您可以将现有模型标记为新名称,并在不同的命名空间和存储库下发布它们
# Tag a pulled model under a new name
$ docker model tag ai/smollm2 myorg/smollm2
# Push it to Docker Hub
$ docker model push myorg/smollm2有关更多详细信息,请参阅 docker model tag 和 docker model push 命令文档。
您还可以将 GGUF 格式的模型文件打包为 OCI Artifact 并将其发布到 Docker Hub。
# Download a model file in GGUF format, for example from HuggingFace
$ curl -L -o model.gguf https://hugging-face.cn/TheBloke/Mistral-7B-v0.1-GGUF/resolve/main/mistral-7b-v0.1.Q4_K_M.gguf
# Package it as OCI Artifact and push it to Docker Hub
$ docker model package --gguf "$(pwd)/model.gguf" --push myorg/mistral-7b-v0.1:Q4_K_M有关更多详细信息,请参阅 docker model package 命令文档。
故障排除
显示日志
要解决问题,请显示日志
选择 模型 并选择 日志 选项卡。
检查请求和响应
检查请求和响应有助于诊断模型相关问题。例如,您可以评估上下文使用情况以验证您是否保持在模型的上下文窗口内,或者显示请求的完整正文以在使用框架进行开发时控制传递给模型的参数。
在 Docker Desktop 中,要检查每个模型的请求和响应
- 选择 模型 并选择 请求 选项卡。此视图显示所有模型的所有请求
- 发送请求的时间。
- 模型名称和版本
- 提示/请求
- 上下文使用情况
- 生成响应所需的时间。
- 选择其中一个请求以显示更多详细信息
- 在 概述 选项卡中,查看令牌使用情况、响应元数据和生成速度,以及实际的提示和响应。
- 在 请求 和 响应 选项卡中,查看请求和响应的完整 JSON 有效负载。
注意您还可以在选择模型后选择 请求 选项卡时显示特定模型的请求。